This means that the values in this column are unique, and each value
can be used to identify a single row in this table.
AUTOINCREMENT
For integer values, this means that the value is automatically
filled in and incremented with each row insertion. Not supported in all
databases.
UNIQUE
This means that the values in this column have to be unique, so you
can’t insert another row with the same value in this column as another
row in the table. Differs from the PRIMARY KEY in that it
doesn’t have to be a key for a row in the table.
NOT NULL
This means that the inserted value can not be
NULL.
CHECK (expression)
This allows you to run a more complex expression to test whether the
values inserted are valid. For example, you can check that values are
positive, or greater than a specific size, or start with a certain
prefix, etc.
FOREIGN KEY
This is a consistency check which ensures that each value in this
column corresponds to another value in a column in another table. For
example, if there are two tables, one listing all Employees by ID, and
another listing their payroll information, the FOREIGN KEY
can ensure that every row in the payroll table corresponds to a valid
employee in the master Employee list.
Table Structure
Foreign Key
A foreign key is a field (or collection of fields) in one table, that
refers to the primary key in another table.
The foreign key constraint prevents invalid data from being inserted
into the foreign key column, because it has to be one of the values
contained in the parent table.
1 2 3 4
ALTER TABLE students ADD CONSTRAINT fk_class_id -- name the constraint FOREIGN KEY (class_id) -- use class_id column in students as FK REFERENCES classes (id); -- links to id in table classes
Deleting the constraint won’t delete the column used as FK.
1 2
ALTER TABLE students DROPFOREIGN KEY fk_class_id;
Indexing
We can index frequently accessed columns to speed up querying.
Indexes are based on hash, so the more spread out the data in index
columns are, the better indexing performs.
索引的效率取决于索引列的值是否散列,即该列的值如果越互不相同,那么索引效率越高。反过来,如果记录的列存在大量相同的值,例如gender列,大约一半的记录值是M,另一半是F,因此,对该列创建索引就没有意义。
1 2 3 4 5
ALTER TABLE students ADD INDEX idx_score (score); -- indexing named as idx_score; it indexes column score
ALTER TABLE students ADD INDEX idx_name_score (name, score); -- create a two-column indexing of name and score
Unique
Add a UNIQUE constraint to make sure the uniqueness of
student’s name (Assume no two students have the same name).
1 2
ALTER TABLE students ADD CONSTRAINT uni_name UNIQUE (name);
Querying Table
注意字符串用的都是单引号 ' '.
Conditionals
=: equal
<>: not equal
LIKE: case insensitive exact string comparison;
% is wildcard. 'ab%' matches
‘ab’,‘abc’,‘abcd’
_ is “appeared once”. LIKE "ab_" matches
“abc”, but not “ab” or “abcd”
BETWEEN … AND …: number is within range of two values
(inclusive). e.g. col_name BETWEEN 1.5 AND 10.5
IN (…): number exists in a list.
e.g. col_name IN (2, 4, 6)
NOT …: to negate a predicate
1 2 3 4 5 6 7 8
-- sometimes we don't need FROM -- this is usually used to test connection to data base SELECT1 SELECT100+200
SELECT*FROM students WHERE (score <80OR score >90) AND gender ='M'; SELECT*FROM students WHERE (NOT class_id <>2) AND score LIKE'8%' ;
Projections
1 2
-- rename column score as points SELECT id, score points, name FROM students;
Orders
Query results are usually ordered by PK. If we want to change the
order, we can
1 2 3 4 5 6 7 8 9 10 11
-- order by score (default in ascending order 正序) SELECT id, name, score FROM students ORDERBY score;
-- order by score and gender (descending score and ascending id) SELECT id, name, score FROM students ORDERBY score DESC, id;
-- together with WHERE SELECT id, name, gender, score FROM students WHERE class_id =1 ORDERBY score DESC;
Partial Results
Query result is sometimes in huge amount. In this case, we only want
to show part of the result.
1 2 3 4 5 6 7
-- show only 3 result SELECT id, name, gender, score FROM students ORDERBY score DESC LIMIT 3;
-- show only 3 result, starting from the 7th. SELECT id, name, gender, score FROM students ORDERBY score DESC LIMIT 3OFFSET6;
Groups
1 2 3 4 5
-- return #records in TABLE students, and name it num SELECTCOUNT(*) num FROM students;
-- return #records whose gender is 'M', and name the result "boys" SELECTCOUNT(*) boys FROM students WHERE gender ='M';
和 COUNT 类似的还有以下函数:
函数
说明
SUM
计算某一列的合计值,该列必须为数值类型
AVG
计算某一列的平均值,该列必须为数值类型
MAX
计算某一列的最大值,如果是字符串类型则返回排序最后的字符
MIN
计算某一列的最小值,如果是字符串类型则返回排序最前的字符
其中,如果 WHERE
条件没有匹配到任何行,COUNT()会返回0,而SUM()、AVG()、MAX()和MIN()会返回NULL。
分完组后,我们不能再用 WHERE
对组进行筛选,以组为级别进行筛选需要 HAVING.
1 2 3 4 5 6 7 8 9 10 11 12 13
-- 按照 class_id 分组(class_id=1, 2, 3, ... 各一组), 分别返回每一组的总记录数 SELECT class_id, COUNT(*) num FROM students GROUPBY class_id;
-- 分完组后, SELECT class_id, COUNT(*) num FROM students GROUPBY class_id HAVINGCOUNT(*) >36;
-- 对于像 name 这种在一个组内并不是相同的值,会返回 NULL / 报错 -- 因此对于聚合查询,我们只能放入聚合查询的 col 名或者一些其他的聚合函数 SELECT name, class_id, COUNT(*) num FROM students GROUPBY class_id;
-- 查询每个班级男女分别的平均分 SELECT class_id, gender, AVG(score) FROM students GROUPBY gender, class_id ORDERBY class_id, gender;
Multiple Tables
When you select from more than one table, database will return the
Cartesian product of the results.
1 2 3 4 5
SELECT s.id sid, s.name, s.gender, s.score, c.id cid, c.name cname FROM students s, classes c WHERE s.gender ='M'AND c.id =1;
RIGHT OUTER JOIN返回右表都存在的行。如果某一行仅在右表存在,那么结果集就会以NULL填充剩下的字段。
LEFT OUTER JOIN则返回左表都存在的行。如果我们给students表增加一行,并添加class_id=5,由于classes表并不存在id=5的行,所以,LEFT
OUTER
JOIN的结果会增加一行,对应的class_name是NULL:
FULL OUTER JOIN,它会把两张表的所有记录全部选择出来,并且,自动把对方不存在的列填充为NULL:
1 2 3 4 5 6 7 8
-- Join 指令模板 SELECT ... FROM tableA ??? JOIN tableB ON tableA.column1 = tableB.column2;
-- 上文使用的例子对应的指令 SELECT s.id, s.name, s.class_id, c.name class_name, s.gender, s.score FROM students s FULLOUTERJOIN classes c ON s.class_id = c.id;
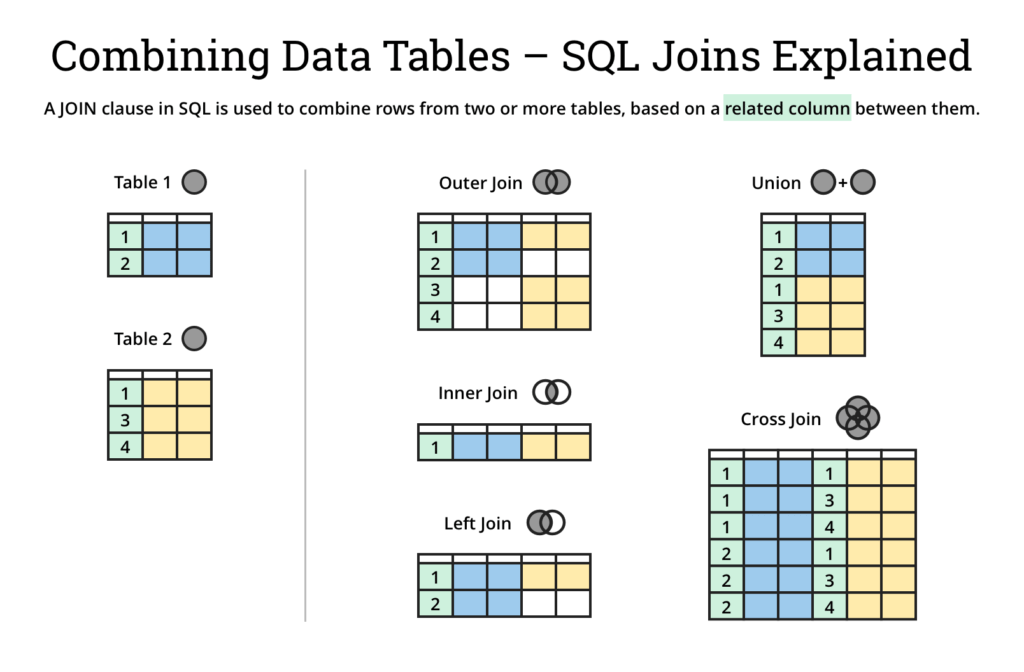
Join in Graphs
Null
An alternative to NULL values in your database is to
have data-type appropriate default values, like 0 for numerical
data, empty strings for text data, etc. But if your database needs to
store incomplete data, then NULL values can be appropriate
if the default values will skew later analysis (for example, when taking
averages of numerical data).
1 2 3
-- select all non-null values SELECTcolumn, another_column, … FROM mytable WHERE column_name IS/ISNOT NULL
Operating on Rows
Insert
When we insert something into the table, we don’t have to specify
value of the primary key column. Because the primary key is
automatically calculated by the database.