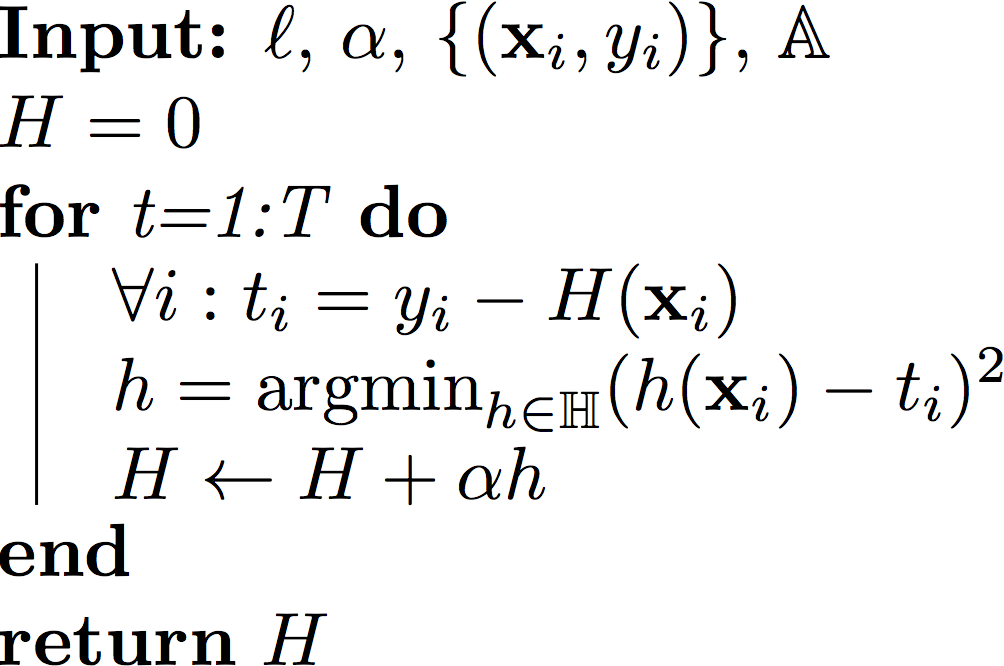Scenario: Hypothesis class H, whose set of classifiers has large bias and the training error is high (e.g. CART trees with very limited depth.)
Famous question: Can weak learners (h) be combined to generate a strong learner with low bias?
Answer: Yes!
Solution: Create ensemble classifier HT(x)=∑t=1Tαtht(x). This ensemble classifier is built in an iterative fashion. In iteration t we add the classifier αtht(x) to the ensemble. At test time we evaluate all classifier and return the weighted sum.
Let ℓ denote a (convex and differentiable) loss function.
Assume we have already finished t iterations and already have an ensemble classifier Ht(x). Now at iteration t+1 we add one more weak learner ht+1 that minimizes the loss:
As before, we find minimum by doing gradient descent. However, instead of finding a parameter that minimizes the loss function, we find a functionh this time. Therefore we will do gradient descent in function space.
Given H, we want to find the step-size α and the weak learner h to minimize the loss ℓ(H+αh). Use Taylor Approximation on ℓ(H+αh):
This approximation only holds within a small region around ℓ(H). We therefore fix α to a small constant (e.g. α≈0.1). With the step-size α fixed, we can use the approximation above to find an almost optimal h:
In function space, inner product is defined as <f,g>=x∫f(x)g(x)dx. This is intractable most of the time because x comes from an infinite space. Since we only have training set, we can rewrite the inner product as <f,g>=∑i=1nf(xi)g(xi), where f is the gradient, g is model h.
Note ∂H∂ℓ is the derivative of a function with respect to another function, which is tricky, so we need a work-around. ℓ(H)=∑i=1nℓ(H(xi)), so we can write ∂H∂ℓ(xi)=∂[H(xi)]∂ℓ, the derivative of the loss with respect to a specific function value. Now the optimization problem becomes:
In this way, we decrease the loss by adding this new model ht+1. However, if the this inner product is >0 there is nothing we can do with gradient descent.
First, we assume that ∑i=1nh2(xi) = constant. So we are essentially fixing the vector h in ∑i=1nh(xi)ri to lie on a circle, and we are only concerned with its direction but not its length.
Define the negative gradient as ti=−ri=−∂H(xi)∂ℓ.
h=argminh∈Hi=1∑nrih(xi)=argminh∈H−2i=1∑ntih(xi)=argminh∈Hi=1∑nconstantti2−2tih(xi)+constant(h(xi))2=argminh∈Hi=1∑n(h(xi)−ti)2 original AnyBoost formulationSwapping in ti for −ri and multiply by constant 2Adding constant ∑iti2+h(xi)2
At the second last step, note ti2 is the negation of loss function with respect to the ensemble H we already chose, independent of the model h we are choosing, so it is a constant. On the other hand, we constrained in the assumptions part that ∑i=1nh2(xi) is a constant.
Therefore, we translate the original problem about finding a regression tree that minimizes an arbitrary loss function to this problem of finding a regression tree that minimizes the squared loss with our new “label” t and we are fitting t now.
If the loss function ℓ is the squared loss, i.e. ℓ(H)=21∑i=1n(H(xi)−yi)2, there is a special meaning of this t: it is easy to show that
which is simply the error between our current prediction and the correct label, so this newly added model is just fitting the error current ensemble model has. However, it is important to keep in mind that you can use any other differentiable and convex loss function ℓ and the solution for your next weak learner h will always be the regression tree minimizing the squared loss.
Step-size: We perform line-search to obtain best step-size α.
Loss function: Exponential loss ℓ(H)=∑i=1ne−yiH(xi)
All data points must have the correct label, since we are using the exponential loss here and will get a very bad result if concentrate all our weights on noise (wrongly labeled data).
At each update step, first we compute the gradient ri=∂H(xi)∂ℓ=−yie−yiH(xi). For notational convenience, define wi=Z1e−yiH(xi), where Z=∑i=1ne−yiH(xi) is a normalizing factor so that ∑i=1nwi=1. Note that the normalizing constant Z is identical to the loss function. Each weight wi can now be interpreted as the relative contribution of the training point (xi,yi) towards the overall loss. Therefore, at each update step, we reweight the data points according to current loss and in later part of the algorithm will prioritize those points we got really wrong.
We can translate the optimization problem of minimizing loss into a optimization probelm of minimizing the weighted classification error.
h(xi)=argminh∈Hi=1∑nrih(xi)=argminh∈H−i=1∑nyie−H(xi)yih(xi)=argminh∈H−i=1∑nwiyih(xi)=argminh∈Hi:h(xi)=yi∑wi−i:h(xi)=yi∑wi=argminh∈Hi:h(xi)=yi∑wi(substitute in: ri=e−H(xi)yi)(substitute in: wi=Z1e−H(xi)yi,Z is constant)(yih(xi)∈{+1,−1} with h(xi)yi=1⟺h(xi)=yi)(i:h(xi)=yi∑wi+i:h(xi)=yi∑wi=1)(This is the weighted classification error.)
Let us denote this weighted classification error as ϵ=∑i:h(xi)yi=−1wi, or to say the weights of those wrongly classified points. So for AdaBoost, we only need a classifier that reduces this weighted classification error of these wrongly labeled training samples. It doesn’t have to do all that well, in order for the inner-product ∑irih(xi) to be negative, it just needs less than ϵ<0.5weighted training error.
In the previous example, GBRT, we set the stepsize α to be a small constant. As it turns out, in the AdaBoost setting we can find the optimal stepsize (i.e. the one that minimizes ℓ the most) in closed form every time we take a “gradient” step.
If we take the derivative of loss function ℓ with respect to α, we will actually find out that there is a nice closed form for α:
After you take a step, i.e. Ht+1=Ht+αh, you need to re-compute all the weights and then re-normalize. However, if we update w using the formula below, w will remain normalized.
The inner loop can terminate as the error ϵ=21, and in most cases it will converge to 21 over time. In that case the latest weak learner h is only as good as a coin toss and cannot benefit the ensemble (therefore boosting terminates). Also note that if ϵ=21 the step-size α would be zero.
We can in fact show that the training loss is decreasing exponentially! Even further, we can show that after O(log(n)) iterations your training error must be zero. In practice it often makes sense to keep boosting even after you make no more mistakes on the training set.