Back Propagation
Reverse Mode Automatic Differentiation¶
We need to fix an output in the NN. For most cases, we just use the final output of the NN ( stands for loss). For each intermediate output value , we want to compute partial derivatives .
Same as before: we replace each number/array with a pair, except this time the pair is not but instead where is our final output (loss of NN). Observe that always has the same shape as .
Deriving Backprop from the Chain Rule¶
Single Variable¶
Suppose that the output can be written as
Here, represents the immediate next operation that takes (producing a new intermediate ), and represents all the rest of the computation between and . By the chain rule,
Therefore, to compute , in addition to - the derivative of all the other intermediate computation, we only need to use “local” information that’s available in the program around where is computed and used. That is, if ignore , we can compute together when we compute .
Multi Variable¶
More generally, suppose that the output can be written as
Here, the represent the immediate next operations that take ; the are the output by these operations, and represents all the rest of the computation between and . By the multivariate chain rule,
Note here we are talking about the more general case, where are all vectors. So takes in a vector and outputs a vector When we take the derivative of at , we get a matrix and we call this matrix
Again, we see that we can compute using only and “local” information .
Computing Backprop¶
When to Compute?¶
Note the value is computed as follows: So when we are computing , which is also when we ideally want to compute , the value of is not yet available. Without , we cannot compute , which is a necessary part to get . Therefore we cannot compute along with
Therefore, we cannot compute until after we’ve computed everything between and . So the solution is to remember the order in which we computed stuff in between and , and then compute their gradients in the reverse order.
Computational Graph¶
We draw a graph to indicate the computational dependencies, just like the above:
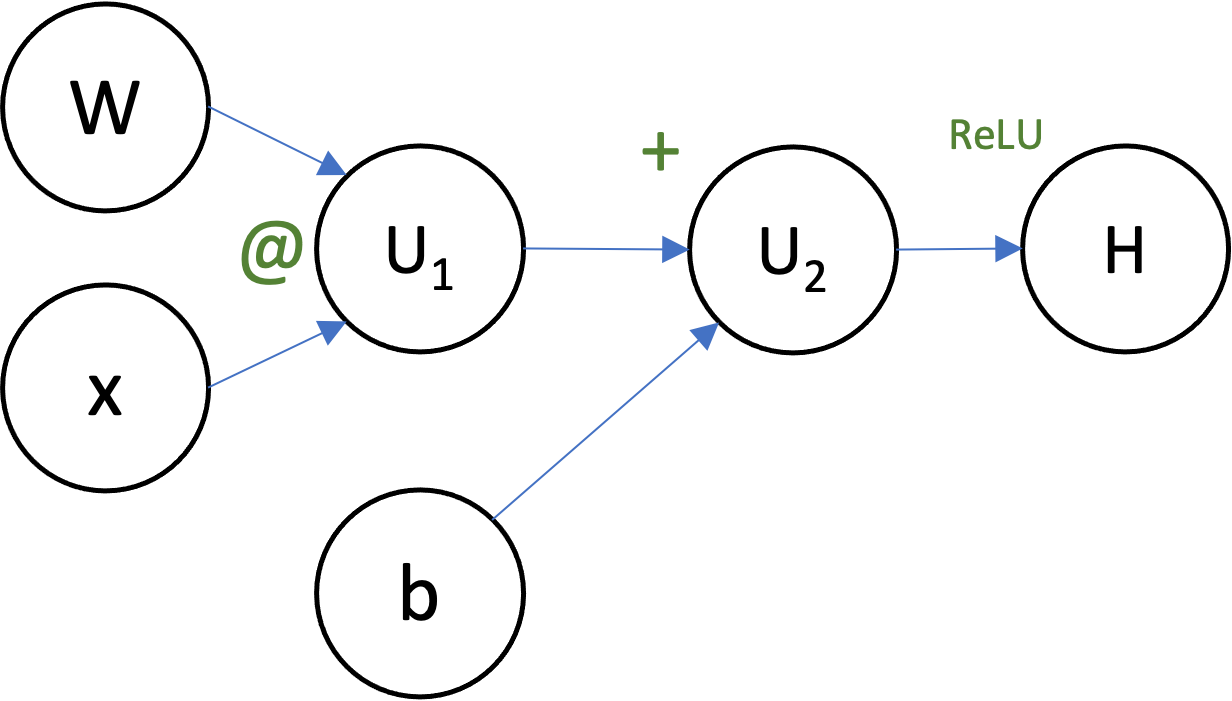
- node represents an scalar/vector/tensor/array
- Edges represent dependencies, where means that was used to compute
Algorithm¶
Generally speaking,
For each tensor, initialize a gradient “accumulator” to 0. Set the gradient of with respect to itself to 1.
For each tensor that depends on, in the reverse order of computation, compute - derivative of with respect to . This is obtainable because when we get to , all the intermediate value between and are already computed.
Once this step is called for , its gradient will be fully manifested in its gradient accumulator.
In a computational graph, this means
For each tensor, initialize a gradient “accumulator” to 0. Set the gradient of with respect to itself to 1.
For each tensor pointing to , start from and go back along the path, compute - derivative of with respect to . Specifically, we compute this value by looking at all its direct descendants where We can do this because are the nodes between and , when we get to , all values are already computed.
Once this step is called for , computation is done.