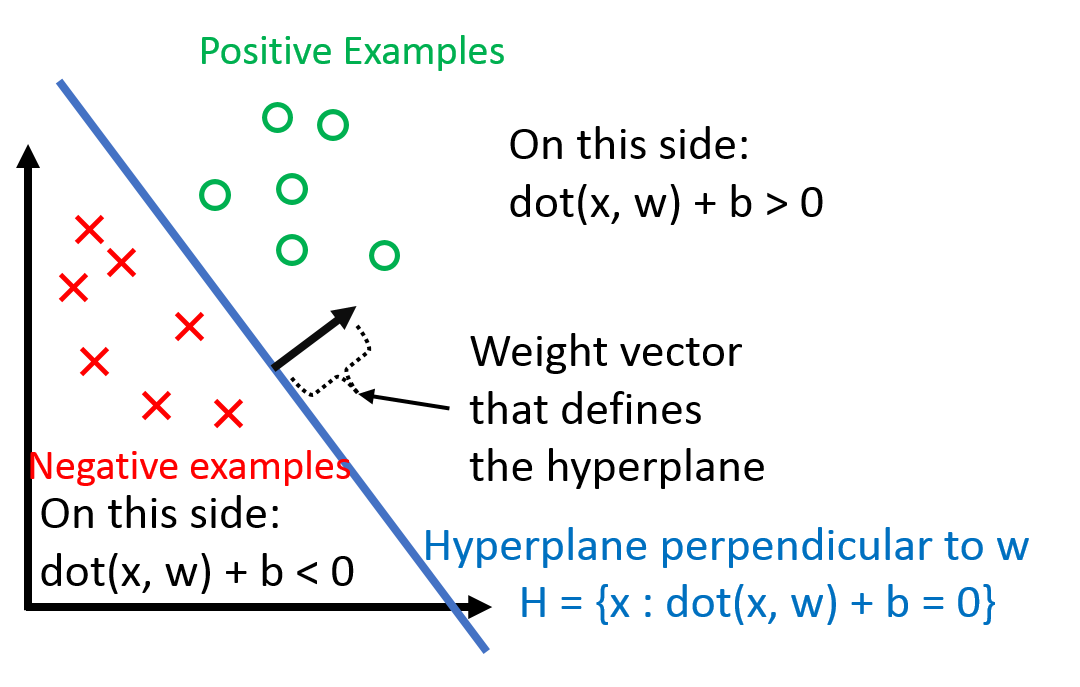
w is the normal vector of the hyperplane. It defines this hyperplane. b is the bias term (without the bias term, the hyperplane that w defines would always have to go through the origin). Dealing with b can be a pain, so we ‘absorb’ it into the feature vector w by adding one additional constant dimension. Under this convention,
where “classified correctly” means that xi is on the correct side of the hyperplane defined by w. Also, note that the left side depends on yi∈−1,+1 (it wouldn’t work if, for example yi∈0,+1).
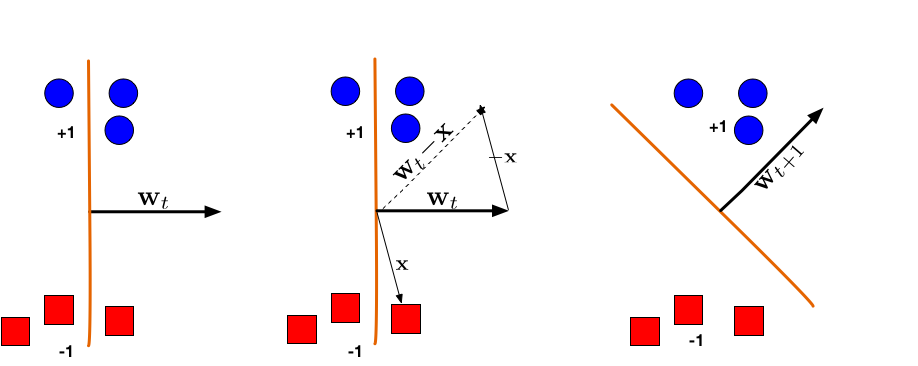
(Left:) The hyperplane defined by wt misclassifies one red (-1) and one blue (+1) point. (Middle:) The red point x is chosen and used for an update. Because its label is -1 we need to subtractx from wt. (Right:) The udpated hyperplane wt+1=wt−x separates the two classes and the Perceptron algorithm has converged.
Note we updated w based on point x because we classified x incorrectly, so we want to move to a more correct direction. Let’s look at the classification result of x after such an update: w′⋅x=(w+yx)⋅x=w⋅x+yx2>w⋅x. Though we still do not know whether x is now labelled correctly (w′⋅x), but at least we know the classification result is somewhat better because it increased a bit.
If a data set is linearly separable, the Perceptron will find a separating hyperplane in a finite number of updates. (If the data is not linearly separable, it will loop forever.)
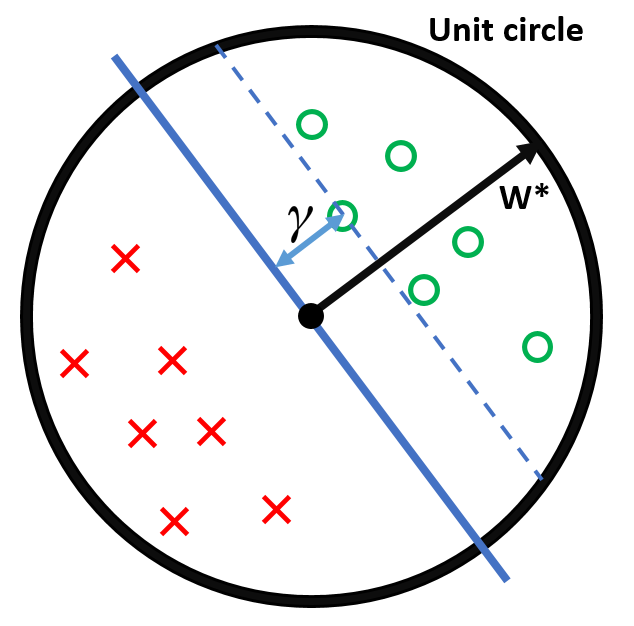
The argument goes as follows: Suppose the answer classification hyperplane exists, so ∃w∗ such that ∀(xi,yi)∈D,yi(x⊤w∗)>0.
Now, suppose that we rescale each data point and the w∗ such that all data points are within a unit hypersphere and w∗ normal vector of hyperplane is exactly on the unit sphere.
Let us define the Margin γ of the hyperplane w∗ as γ=min(xi,yi)∈D∣xi⊤w∗∣: 即所有数据点中离 hyperplane 最近的距离
Observe: ∀x,we have y(x⊤w∗)=∣x⊤w∗∣≥γ. Because w∗ is a perfect classifier, so all training data points (x,y) lie on the “correct” side of the hyper-plane and therefore y=sign(x⊤w∗). The second inequality follows directly from the definition of the margin γ.
To summarize our setup:
All inputs xi live within the unit sphere
There exists a separating hyperplane defined by w∗, with ∥w∗∥=1 (i.e. w∗ lies exactly on the unit sphere).
γ is the distance from this hyperplane (blue) to the closest data point.
y(x⊤w)≤0: This holds because x is misclassified by w - otherwise we wouldn’t make the update.
y(x⊤w∗)≥γ>0: First holds directly from definition of margin γ; second holds because w∗ is a separating hyper-plane and classifies all points correctly.
2y(w⊤x)<0 as we had to make an update, meaning x was misclassified
0≤y2(x⊤x)≤1 as y2=1 and all x⊤x≤1 (because ∥x∥≤1).
This means that for each update, w⊤w grows by at most 1.
Now remember from the Perceptron algorithm that we initialize w=0. Hence, initially w⊤w=0 and w⊤w∗=0 and after M updates the following two inequalities must hold:
w⊤w∗≥Mγ
w⊤w≤M.
We can then complete the proof:
Mγ≤w⊤w∗=∥w∥cos(θ)≤∣∣w∣∣=w⊤w≤M⇒Mγ≤M⇒M2γ2≤M⇒M≤γ21By (1)by definition of inner-product, where θ is the angle between w and w∗.by definition of cos, we must have cos(θ)≤1.by definition of ∥w∥By (2)And hence, the number of updates M is bounded from above by a constant.
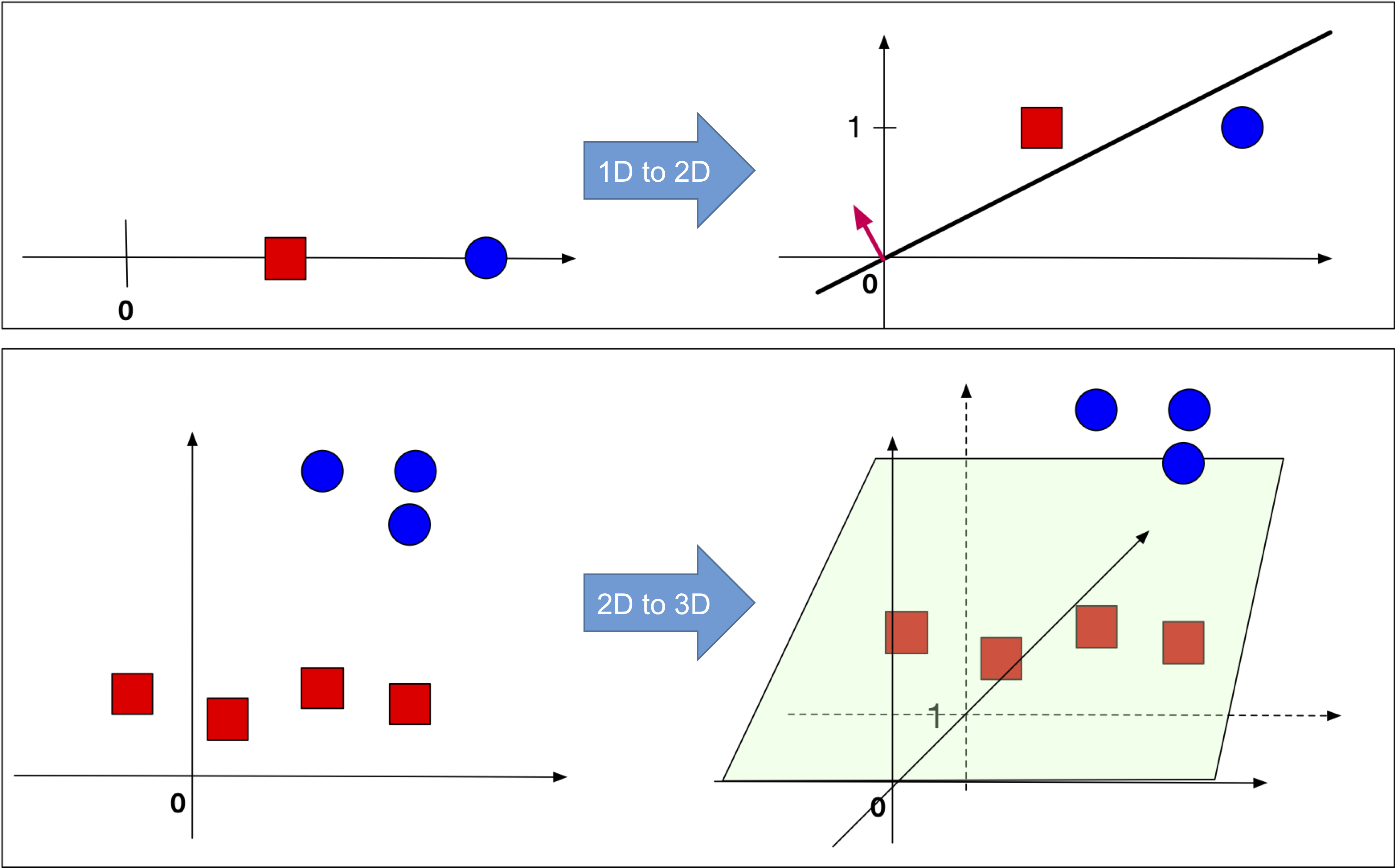
Perceptron suffers from the limitation of a linear model: If no separating hyperplane exists, perceptron will NEVER converge. (There will always be some points on the wrong side and it will iterate forever)
It does not generalize well either. Though it corrects all data points correctly, the decision boundary is almost arbitrary. And if a test point is given, Perceptron will very likely to classify it to the wrong side.
Especially suffered from the 1st problem, AI winter came as a result.