Principal Component Analysis
PCA finds the low dimensional structure of high dimensional data.
Basic Ideas¶
Whereas k-means clustering sought to partition the data into homogeneous subgroups, principal component analysis (PCA) will seek to find, if it exists, low-dimensional structure in the data set (). The features in which the data vary the most describes this lower-dimensional subspace.
PCA finds a low-dimensional representation of the data that captures most of the interesting behavior. Here, “interesting” will be defined as variability. This is analogous to computing “composite” features (i.e. linear combinations of entries in each that explain most of the variability in the data.)
Take a simple example: if there exists one unit vector such that for some scalar , then we can roughly represent all by a much smaller number of “features.” (in this case only one ) If we accept that is a valid “feature” for all of our data, we could approximate our data using only the scalar to describe how behaves on that feature . More concisely, we say that the approximately lie in , a subspace of dimension 1.
This is illustrated in the next figure, where we see two dimensional data that approximately lies in a one dimensional subspace . If we know what is, we can approximate all data using only .
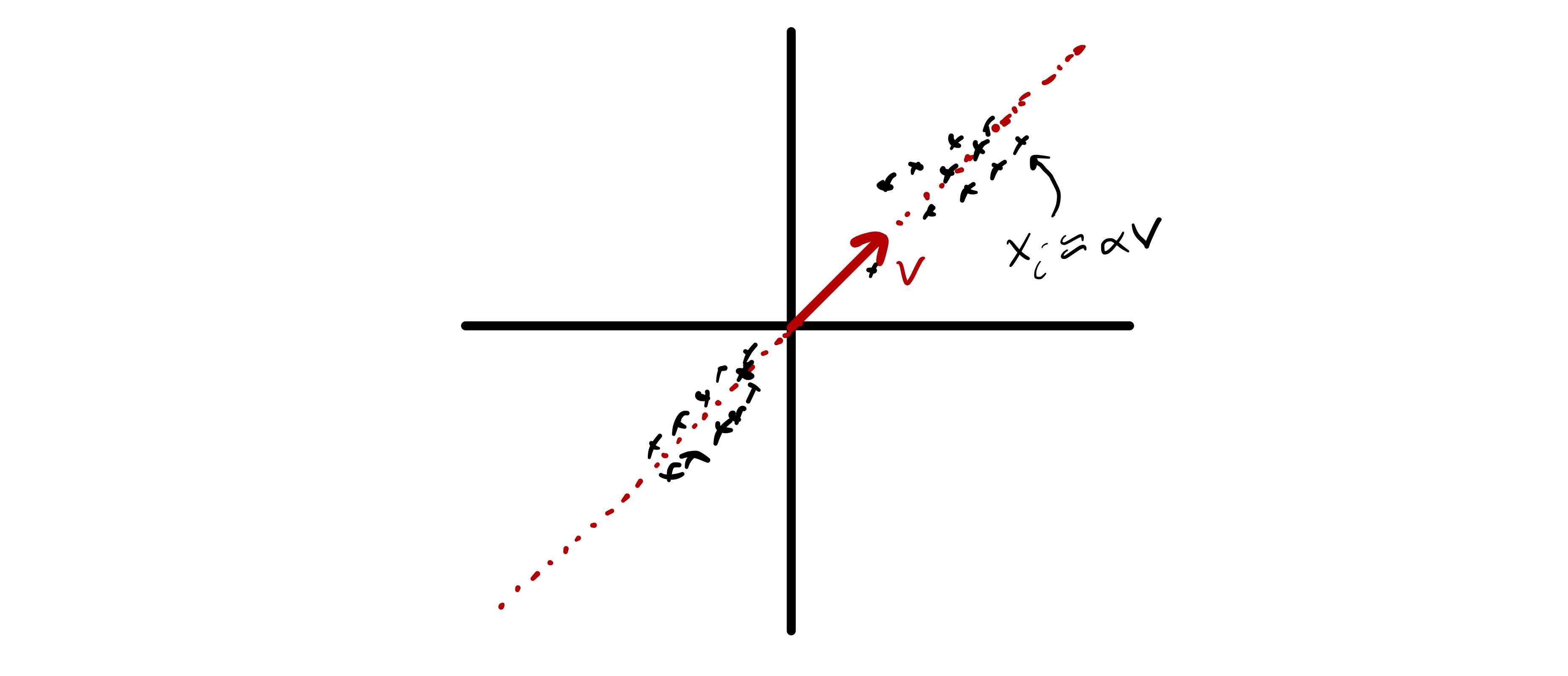
Centering the data¶
Typically in unsupervised learning, we are interested in understanding relationships between data points and not necessarily bulk properties of the data. If the data has a sufficiently large mean, i.e. is sufficiently far from zero, the best approximation of each data point is roughly .
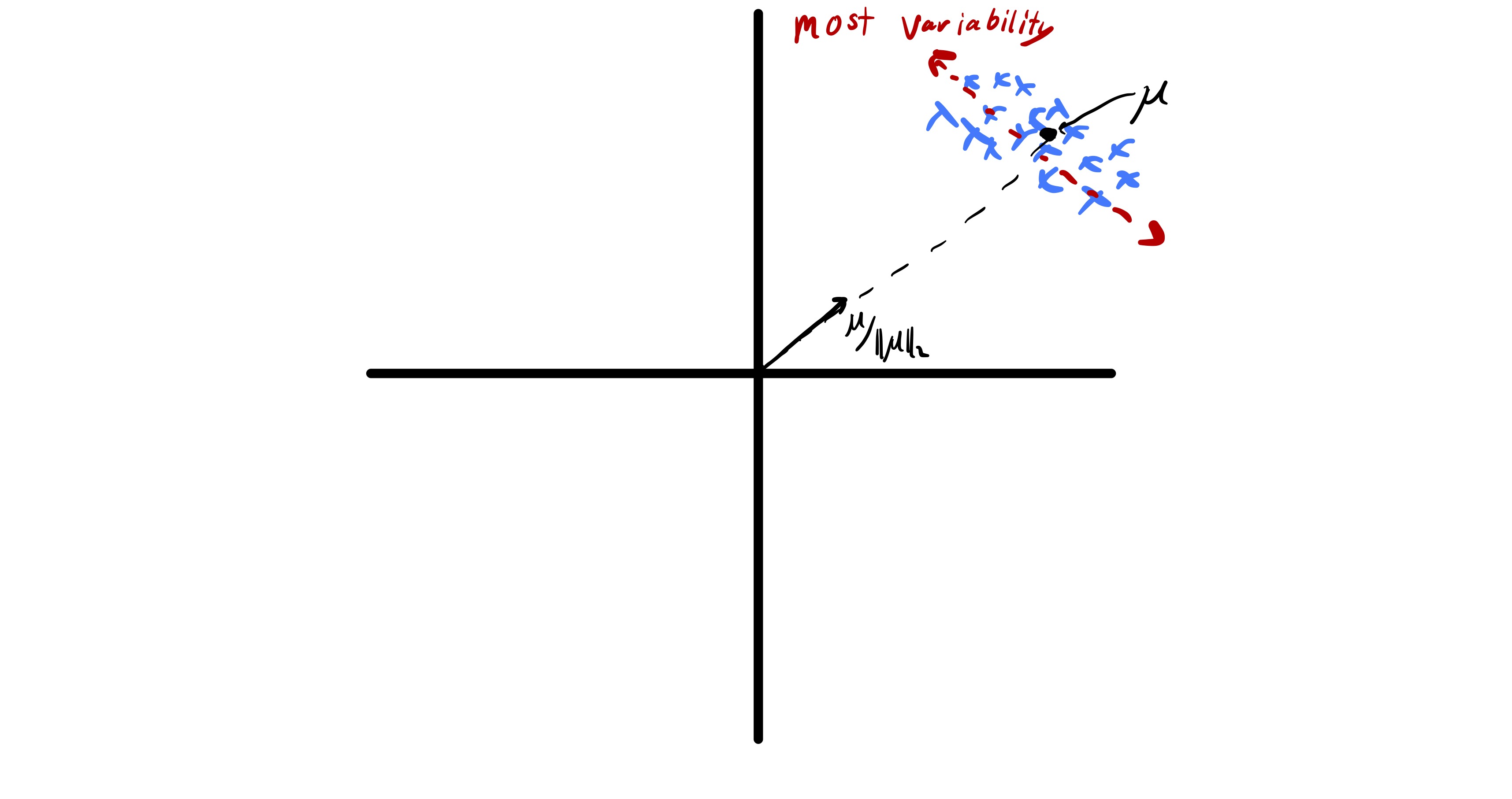
Therefore, to actually understand the relationship between features we would like to center our data before applying PCA by deleting the mean from data. Specifically, we let
where We now simply work with the centered feature vectors and will do so throughout the remainder of these notes.
Maximizing the variance¶
Describing Problem¶
To do PCA, we want to find a small set of composite features that capture most of the variability in the data. To illustrate this point, we will first consider finding a single composite feature that captures the most variability in the data set, then proceed to find the 2nd one, 3rd one...
Mathematically, we want to find a vector such that the sample variance of the scalars
is as large as possible. Note here is the weight: given a data point , for each dimension we assign it a weight , so we have a weighted sum across dimension of the original data point . We try to come up with a composite feature that varies a lot, so we want to maximize the variance of . Note the mean of these is 0 because we did the normalization previous step.
We also have to constrain , or we could artificially inflate the variance by simply increasing the magnitude of the entries in .
We can now formally define the first principal component of a data set:
First principal component: The first principal component of a data set is the vector that solves
We will consider the data matrix
. This allows us to rephrase the problem as
In other words, is the unit vector that makes the matrix as large as possible.
Solving Problem - 1st PC¶
We will show how to find the first PC (Principal Components) in this section. We can use singular value decomposition (SVD). To simplify this presentation we make the reasonable assumption that We can always decompose the matrix as
where is a orthonormal matrix, is an orthonormal matrix, is a diagonal matrix with and . Remind again we have data vectors. Each vector has dimension.
we call the left singular vectors, the right singular vectors, and the singular values. This SVD can be done in . 这些都是 SVD 的定义而已
Claim: we achieve when we have .
Proof: Note is a orthonormal matrix, so its columns constitute a base of . Since we defined , we can write as a combination of these bases:
where (because we want ). We now observe
Therefore,
$$
$$
According to assumption , we achieve max when and for . 证毕
Solving Problem - Other PCs¶
So, the first left singular value of gives us the first principal component of the data. What about finding additional directions? Formally, we want to find such that has the next most variability. 但我们又不能简单地说 , 因为我们可以随便找一个间隔 非常近的 即可。 Therefore, we need to force the second PC to be orthogonal to the first, i.e. . We can actually find the second principal component is in our SVD matrix . Fig.11 illustrates how the first two principal components look for a stylized data set. We see that they reveal directions in which the data varies significantly.
More generally, the SVD actually gives us all the principal components of the data set .
Principal components: Principal component of data set is denoted and satisfies
where is the SVD of
Explaining variability in the data¶
Having obtained the answer, we can look back into our problem in a cleaner way.
The equation above helps us recall that we were maximizing the variance of this vector and the maximized variance is the eigenvalue of matrix . In other words, the singular values reveal the sample variance of . This result generalizes to PCs other than the first one.
If we project our data into the span of the first eigenvectors, the variance we can achieve is the first eigenvalues summed up Formally, the total variability of the data captured by the first PC is . This is the value we kept with interesting composite dimension.
One way we determine - how many vectors we want for PCA is to look at how much of the variance at all dimensions are captured by our composite interesting dimensions:
We want to pick a relatively small such that a relatively big ratio can be achieved. In practice, we can do a similar thing as we did with K-Means: we can pick by identifying when we have diminishing returns in explaining variance by adding more principal components, i.e. looking for a knee in the plot of singular values.
PCA Application¶
We use PCA to reduce dimensions.
A common use of PCA is for data visualization. In particular, if we have high dimensional data that is hard to visualize we can sometimes see key features of the data by plotting its projection onto a few (1, 2, or 3) principal components. For example, if this corresponds to forming a scatter plot of .