When we estimate P(X,Y), we call it generative learning. We try to model the distribution behind the scene - the distribution we draw all our samples from. (Remember how we described this omnipotent distribution when talking about the Bayes Optimal Classifier) We achieve this often by modelling P(X,Y)=P(X∣Y)P(Y).
When we only estimate P(Y∣X) directly, then we call it discriminative learning. We try to model the probability of a label given features. This is more aligned with our common definition of “predicting” things.
Introduction - Estimating Probability Directly From Data¶
Our training consists of the set D={(x1,y1),…,(xn,yn)} drawn from some unknown distribution P(X,Y). Because all pairs are sampled i.i.d., we obtain
We are also interested in using similar technique to estimate P(Y∣X). Because we know if we have P(Y∣X), we can then use the Bayes Optimal Classifier to make predictions. We now want to make some prediction P^(y∣x) based on dataset, and pretend our estimate P^(y∣x) to well describe our real distribution P(Y∣X), so we use P^(y∣x) in place of P(y∣x) in BOC.
So how can we estimate P^(y∣x)? Previously we have derived that P^(y)=n∑i=1nI(yi=y). Similarly, P^(x)=n∑i=1nI(xi=x) and P^(y,x)=n∑i=1nI(xi=x∧yi=y). We can put these two together
Problem: The estimate is only good if there are many training data with the exact same features as x! In high dimensional spaces (or with continuous x), this never happens! So ∣B∣→0 and ∣C∣→0.
Estimating P(y) is easy (assume there are not many classes in this classification problem). We simply need to count how many times we observe each class. Define the fraction of time we see label c as π^c.
Illustration behind the Naive Bayes algorithm: 假设 dim(x)=2, 竖轴是 [x]1, 横轴是 [x]2. 我们实际上有 [x]1,[x]2,y,P 四个量需要表示。y 用颜色来表示,所以应该是个三维图来着,那么高度轴就应该是 probability P,但是这里就画了二维,碍于图画我们只能想象一下了画的这些曲线其实都在高度轴上
fig1: P(x∣y)
fig2: P([x]1∣y)
fig3: P([x]2∣y)
fig4: ∏αP(xα∣y) 这幅图所表示的实际上是三维空间向二维空间的一个投影
We then define our Bayes Classifier as:
h(x)=yargmaxP(y∣x)=yargmaxP(x)P(x∣y)P(y)=yargmaxP(x∣y)P(y)=yargmaxP(y)α=1∏dP(xα∣y)=yargmaxπ^yα=1∏dP(xα∣y)=yargmaxlog(π^y)+α=1∑dlog(P(xα∣y))(P(x) does not depend on y)(by the naive Bayes assumption)previous definition of π^y(as log is a monotonic function)
We will talk about 3 cases where we use Naive Bayes to make predictions. In each case, we make explicit assumptions (refer back to our first chapter to learn about what “assumption” means) about distribution of our samples.
For d dimensional data, think of it as having d independent dices. Each dice corresponds to a feature in our data point. Each dice has some different values. We roll each dice exactly once, record the result in a corresponding entry in our feature vector.
where [θjc]α is the probability of feature α having the value j, given that the label is c. And the constraint indicates that xα must have one of the categories 1,…,Kα.
where l is a smoothing parameter. By setting l=0 we get an MLE estimator, l>0 leads to MAP. If we set l=+1 we get Laplace smoothing. (Here we made an implicit assumption that each category has the same possibility of happening, so we will have lKα imaginary draws and we get [xi]α=j happens l times)
[θ^jc]α=# of samples with label c# of samples with label c that have feature α with value j
We have one die of d values. Roll it multiple times and jot down the number of times each value appeared. Record that number in the entry corresponding to that value. Therefore, the value of the ith feature shows how many times a particular value appeared.
接着以根据词频判别垃圾邮件作为例子,在 multinomial features 中,[x]α=j 就是某个词 α 出现了 j 次。
where θαc is the probability of selecting word xα and ∑α=1dθαc=1 (you have to select one of the d words). This equation describes the probability of having such an email (of some number of appearance times of each vocabulary) given it is a spam (or not).
So, we can use this to generate a spam email, i.e., a document x of class y=spam by picking m words independently at random from the vocabulary of d words using P(x∣y=spam).
If you look back at our Bayesian Classifier definition: argmaxyP(x)P(x∣y)P(y)
The factorial terms are present both at the factor P(x∣y) and the denominator P(x) so they cancel out. And all we need to care about is just the θ and π
Case #3: Continuous Normal Features (Gaussian Naive Bayes)¶
In this situation, we assume each class conditional feature distribution P(xα∣y) originates from a Gaussian distribution with its own mean μα,y and variance σα,y2. So P(xα∣y=c)=N(μαc,σαc2). Since we have the Naive Bayes Assumption, each class conditional feature distribution is actually independent from each other.
To computer μαc,σαc2: The mean μα,y of dimα given label c is just the average feature value of dimension α from all samples with label y. The (squared) standard deviation is simply the variance of this estimate.
The full distribution is P(x∣y)∼N(μy,Σy), where Σy is a diagonal covariance matrix with [Σy]α,α=σα,y2. Diagonal because we have our Naive Bayes Assumption of each dimension being independent from each other.
Let’s start a linear classification with this w and b, we will arrive at our Naive Bayes classifier h(x) as go through the steps below.
$$
w⊤x+b>0⟺α=1∑d[x]α(log(θα+)−log(θα−))[w]α+log(π+)−log(π−)b>0⟺exp(α=1∑d[x]α(log(θα+)−log(θα−))+log(π+)−log(π−))>1⟺α=1∏dexp(logθα−[x]α+log(π−))exp(logθα+[x]α+log(π+))>1⟺α=1∏dθα−[x]απ−θα+[x]απ+>1⟺∏α=1dP([x]α∣Y=−1)π−∏α=1dP([x]α∣Y=+1)π+>1⟺P(x∣Y=−1)π−P(x∣Y=+1)π+>1⟺P(Y=−1∣x)P(Y=+1∣x)>1⟺P(Y=+1∣x)>P(Y=−1∣x)⟺yargmaxP(Y=y∣x)=+1(Plugging in definition of w,b.)(exponentiating both sides)Because alog(b)=log(ba) and exp(a−b)=ebea operationsBecause exp(log(a))=a and ea+b=eaebBecause P([x]α∣Y=−1)=θα−x]αBy the naive Bayes assumption. By Bayes rule (the denominator P(x) cancels out, and π+=P(Y=+1).)i.e. the point x lies on the positive side of the hyperplane iff Naive Bayes predicts +1
. This model is also known as logistic regression. Naive Bayes and Logistic Regression produce asymptotically the same model if the Naive Bayes assumption holds.
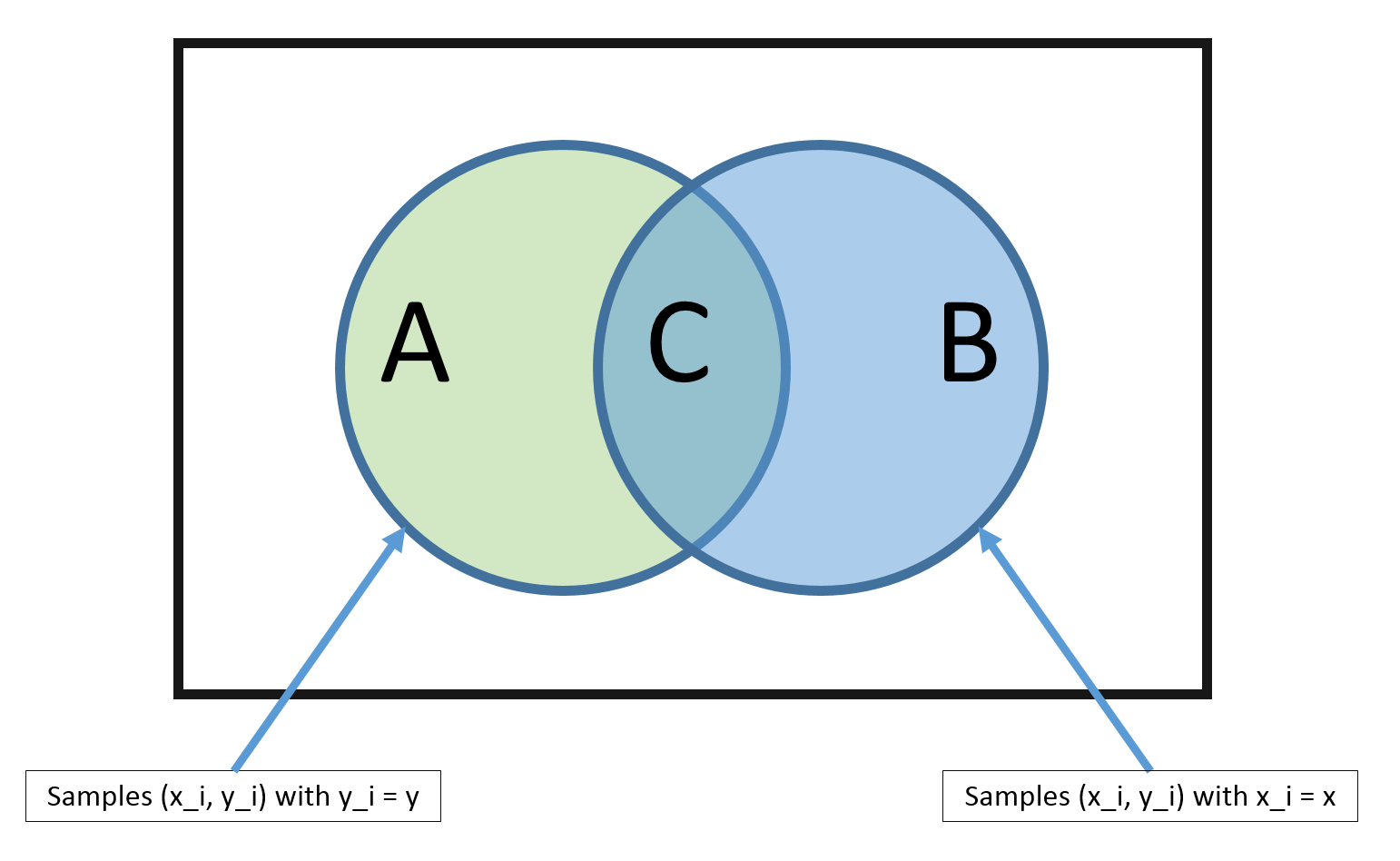
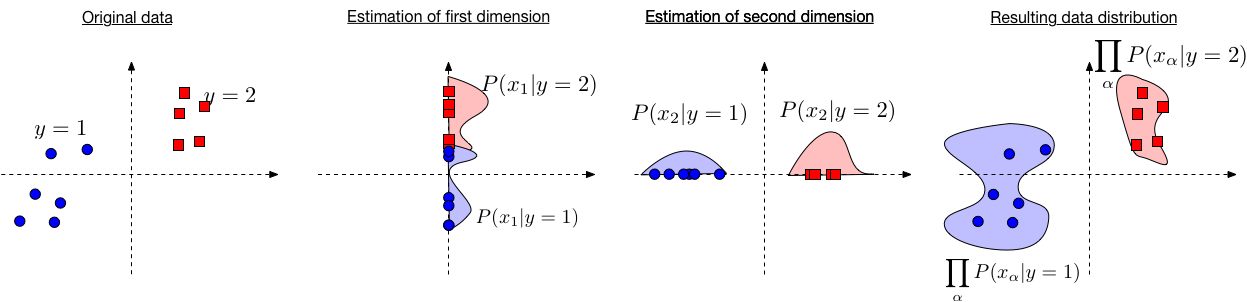 Illustration behind the Naive Bayes algorithm: 假设 , 竖轴是 , 横轴是 . 我们实际上有 四个量需要表示。 用颜色来表示,所以应该是个三维图来着,那么高度轴就应该是 probability ,但是这里就画了二维,碍于图画我们只能想象一下了画的这些曲线其实都在高度轴上
Illustration behind the Naive Bayes algorithm: 假设 , 竖轴是 , 横轴是 . 我们实际上有 四个量需要表示。 用颜色来表示,所以应该是个三维图来着,那么高度轴就应该是 probability ,但是这里就画了二维,碍于图画我们只能想象一下了画的这些曲线其实都在高度轴上