Gradient Descent
from Last Time¶
In the previous lecture on Logistic Regression we wrote down expressions for the parameters in our model as solutions to optimization problems that do not have closed form solutions. Specifically, given data with and we saw that
and
These notes will discuss general strategies to solve these problems and, therefore, we abstract our problem to
where In other words, we would like to find the vector that makes as small as possible.
Assumptions¶
Before diving into the mathematical and algorithmic details we will make some assumptions about our problem to simplify the discussion. Specifically, we will assume that:
- is convex, so local minimum found is a global minimum.
- is at least thrice continuously differentiable, so our Taylor approximations will work later.
- There are no constraints placed on It is common to consider the problem where represents some constraints on (e.g., is entrywise non-negative). Adding constraints is a level of complexity we will not address here.
Defining Minimizer¶
We call a local minimizer of if:
we have
is a global minimizer if
, we have that
Taylor Expansion¶
Recall that the first order Taylor expansion of centered at can be written as
where is the gradient of evaluated at , so . This is the linear approximation of and has error .
Similarly, the second order Taylor expansion of centered at can be written as
where is the Hessian of evaluated at . This is the quadratic approximation of and has error .
Search Direction Methods¶
We can’t really find the exact point where a minimum is achieved. Therefore, the core idea to solve such problem is that given a starting point we construct a sequence of iterates with the goal that as In a search direction method we will think of constructing from by writing it as for some “step” Concretely, this means our methods will have the following generic format:
Input: initial guess
k = 0;
While not converged:
- Pick a step
- and
- Check for convergence; if converged set
Return:
There are two clearly ambiguous steps in the above algorithm: how do we pick and how do we determine when we have converged. We will talk about two main methods used in picking and briefly touch on determining convergence.
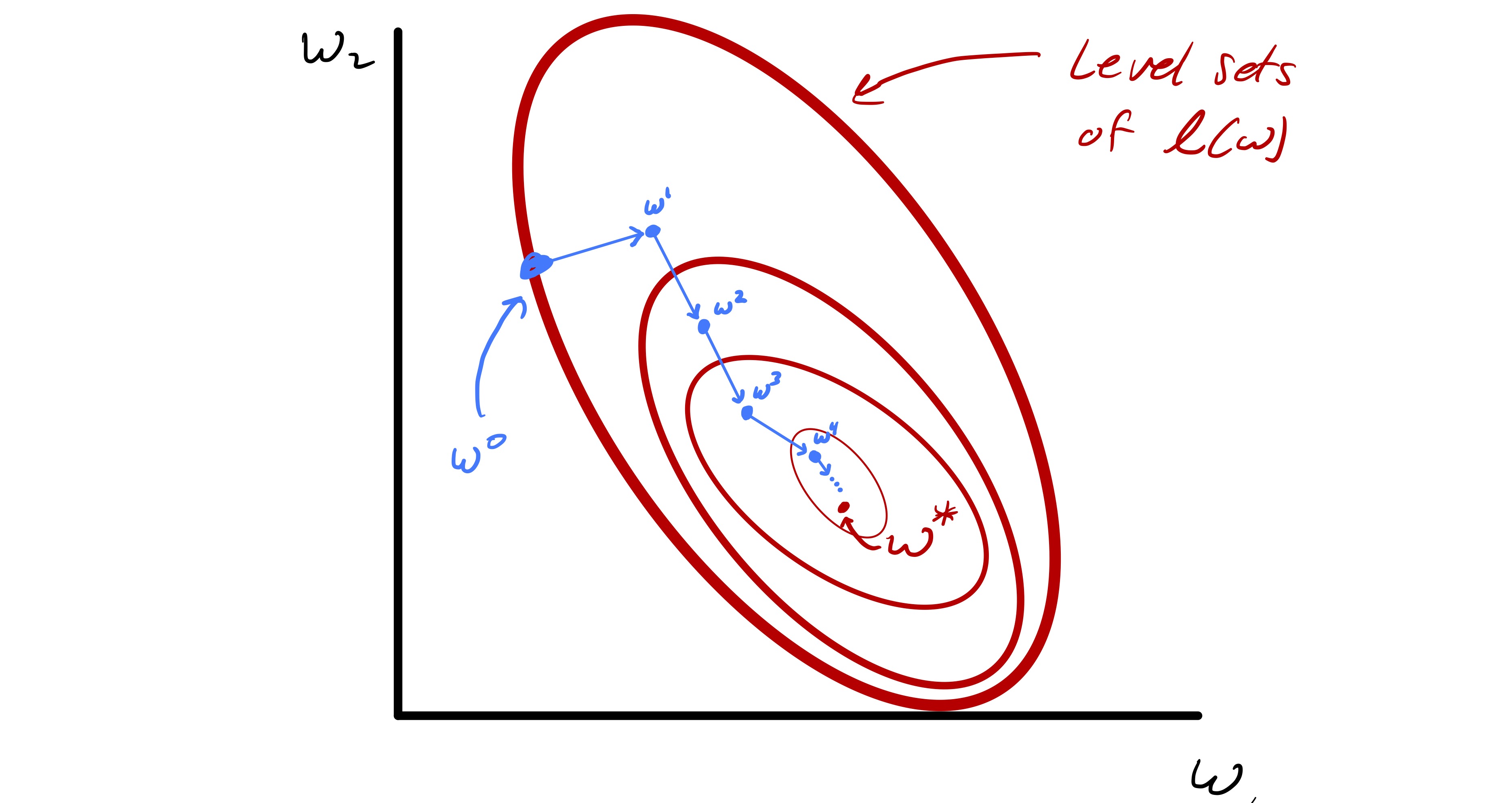
Gradient Descent¶
We use the first order derivative to approximate our function . At first attempt, we try to minimize this function. However, this is not attainable because linear function has no minimum - it just goes all the way to negative infinity. Therefore, we just take some step along this approximation to decrease the value by a bit.
If we directly look at the first order approximation, gradient descent can be also interpreted as follows: given we are currently at determine the direction in which the function decreases the fastest (along the gradient) at this point and update our by taking a step in that direction. Consider the linear approximation to at provided above by the Taylor series:
then the fastest direction to descend is simply , so we just go along the gradient. We want to get a smaller value so go along the negative direction. We go some distance, so set as
¶
is often referred to as the step size in classical optimization, but learning rate in Machine Learning.
- line search - find the best , but expensive so we don’t use it
- fix - might not converge
- decay - set at iteration for any constant , so we take big step early on and take smaller steps as we think we are going to the minimizer. This guarantees convergence.
Adagrad¶
Adagrad (technically, diagonal Adagrad) can be seen as an improvement of decay , where we determine the step size on an entry basis by the steepness of the function - big “decay” for steep direction, and small “decay” for flat direction.
Note in gradient descent, we have the same learning rate across entries, which basically says “we learn the same amount for both rare and common features”. However, we want to have
- rare features - large learning rate. If set the learning rate too small, we won’t be able to change these rarely changed values at all; As we update the model, we always have a small gradient along the rare features, because these rarely occurred events usually have a subtle effect on the model (whether have a pet, whether they follow the traffic light, ...) If we draw a graph of our function, it is flat at this direction.
- common features - low learning rate. If set the learning rate too large, our model will simply jump back and forth because of these common features; As we update the model, we always have a large running gradient along the common features , because they usually have the greatest influence on model (Gender, Race, Age). If we draw a graph of our function, it is steep at this direction.
Therefore, we decrease the step size by a lot along the direction where we already took a large step (that’s along the steep direction, common features) and decrease the step size only by a bit along the direction where we just took a small step (the flat direction, rare features.)
Adagrad keeps track of history of steepness by keeping a running average of the squared gradient at each entry. It then sets a small learning rate for variables with large past gradients and a large learning rate for features with small past gradients.
Input: parameter and initial learning rate
Set and for k = 0;
While not converged:
- Compute the gradient and record values for each entry of the gradient
- For each dimension , calculate the moving sum of squared gradient at dimension : for
- for
- Check for convergence; if converged set
Return:
Convergence¶
Assuming the gradient is non-zero, we can show that there is always some small enough such that In particular, we have
Since and faster than as , we conclude that for some sufficiently small we have that
Newton’s Method¶
Newton’s Method instead uses the second order derivative to approximate . We will pretend our approximation represents very well, finds the minimum point of our quadratic approximation, and claim it also to be the minimum of our original function . This works really well when our function indeed looks similar to a quadratic function locally, but when our approximation is off, the result will be way off and may never converge.
Specifically, we now chose a step by explicitly minimizing the quadratic approximation to at . We can find this minimum because is convex. To accomplish this, we solve
by differentiating and setting the gradient equal to zero. Since the gradient of our quadratic approximation is this implies that solves the linear system
This system is solvable because convex guarantees a positive semi-definite for all . (In fact, we need to solve this function by having a positive definite , which is guaranteed by a strictly convex , but we will introduce a workaround later)
Potential Issues¶
Bad Approximation¶
Newton’s method has very good properties in the neighborhood of a strict local minimizer and once close enough to a solution it converges rapidly. However, if you are far from where the quadratic approximation is valid, Newton’s Method can diverge or enter a cycle. Practically, a fix for this is to introduce a step size and formally set
We typically start with since that is the proper step to take if the quadratic is a good approximation. However, if this step seems poor (e.g. ) then we can decrease at that iteration.
Positive Semi-Definite ¶
- When is convex but not strictly convex we can only assume that is positive semi-definite
- When the original function / our approximation is really flat (remember Hessian matrix represents curvature), so is not invertible.
In principle this means that may not have a solution. Or, if has a zero eigenvalue then we always have infinite solutions. A “quick fix” is to simply solve
for some small parameter instead. This lightly regularizes the quadratic approximation to at and ensures it has a strict global minimizer.
Slow Running Time¶
Newton’s method requires a second order approximation of the original function, which involved the Hessian matrix . There are a lot of parameters to compute compared to a first order approximation.
Checking for convergence¶
- Relative change in the iterates, i.e. for some small .
- A reasonably small gradient, i.e., for some small .