Empirical Risk Minimization
Recap¶
Remember the unconstrained SVM Formulation
where is our prediction, the hinge loss is the SVM’s error function, and the -regularizer reflects the complexity of the solution, and penalizes complex solutions (those with big ).
We can generalize problem of this form as empirical risk minimization with
- loss function : continuous function which penalizes training error
- regularizer : shape your model to the shape your prefer (usually a continuous function which penalizes classifier complexity)
In SVM, , , .
Binary Classification Loss Functions¶
Loss function in binary classification problem is always about - classification result correctness.
| Loss | Usage | Comments |
|---|---|---|
| Hinge-Loss | Standard SVM() Differentiable/Squared Hinge Loss SVM () | When used for Standard SVM, the loss function denotes the size of the margin between linear separator and its closest points in either class. Only differentiable everywhere with , but then it penalizes mistake much more aggressively. |
| Log-Loss | Logistic Regression | Very popular loss functions in ML, since its outputs are well-calibrated probabilities. |
| Exponential Loss | AdaBoost | This function is very aggressive. The loss of a mis-prediction increases exponentially with the value of . This can lead to nice convergence results, for example in the case of Adaboost, but it can also cause problems with noisy data or when you simply mistakenly mislabeled data. |
| Zero-One Loss | Actual Classification Loss | Non-continuous and thus impractical to optimize. |
Figure 4.1: Plots of Common Classification Loss Functions:
- x-axis: , or “correctness” of prediction
- y-axis: loss value
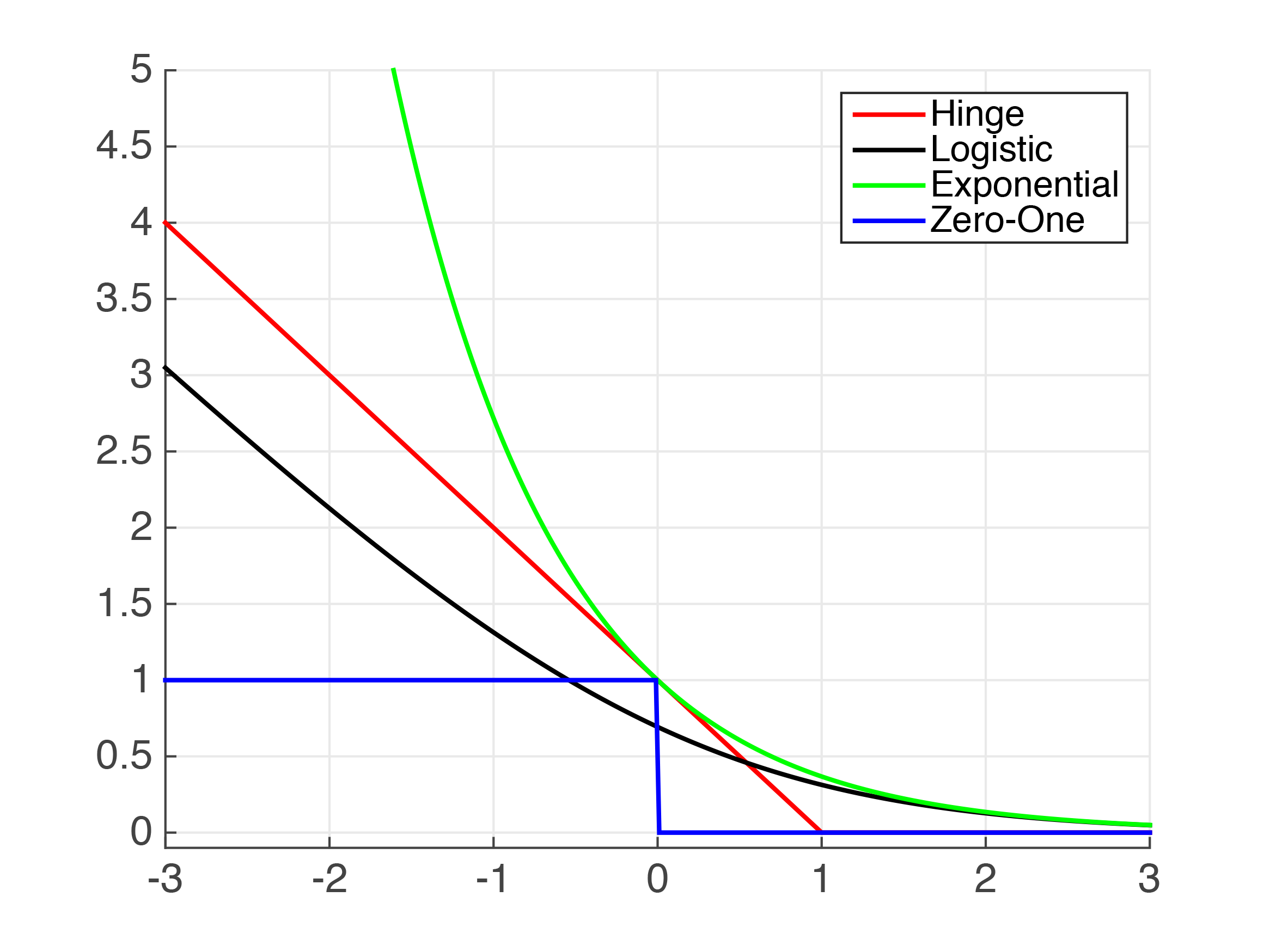
A minor point: from the graph we know that Exponential Loss is a strict upperbound of 0/1 Loss. This will be useful later for proving its convergence.
Regression Loss Functions¶
Loss function in regression is always about the offset between prediction and original value .
| Loss | Comments |
|---|---|
| Squared Loss | Most popular regression loss function Also known as Ordinary Least Squares (OLS) ADVANTAGE: Differentiable everywhere DISADVANTAGE: Somewhat sensitive to outliers/noise Estimates Mean Label |
| Absolute Loss | Also a very popular loss function Estimates Median Label ADVANTAGE: Less sensitive to noise DISADVANTAGE: Not differentiable at 0 (the point which minimization is intended to bring us to) |
| Huber Loss | Also known as Smooth Absolute Loss ADVANTAGE: “Best of Both Worlds” of Squared and Absolute Loss Once-differentiable Takes on behavior of Squared-Loss when loss is small, and Absolute Loss when loss is large. |
| Log-Cosh Loss | ADVANTAGE: Similar to Huber Loss, but twice differentiable everywhere |
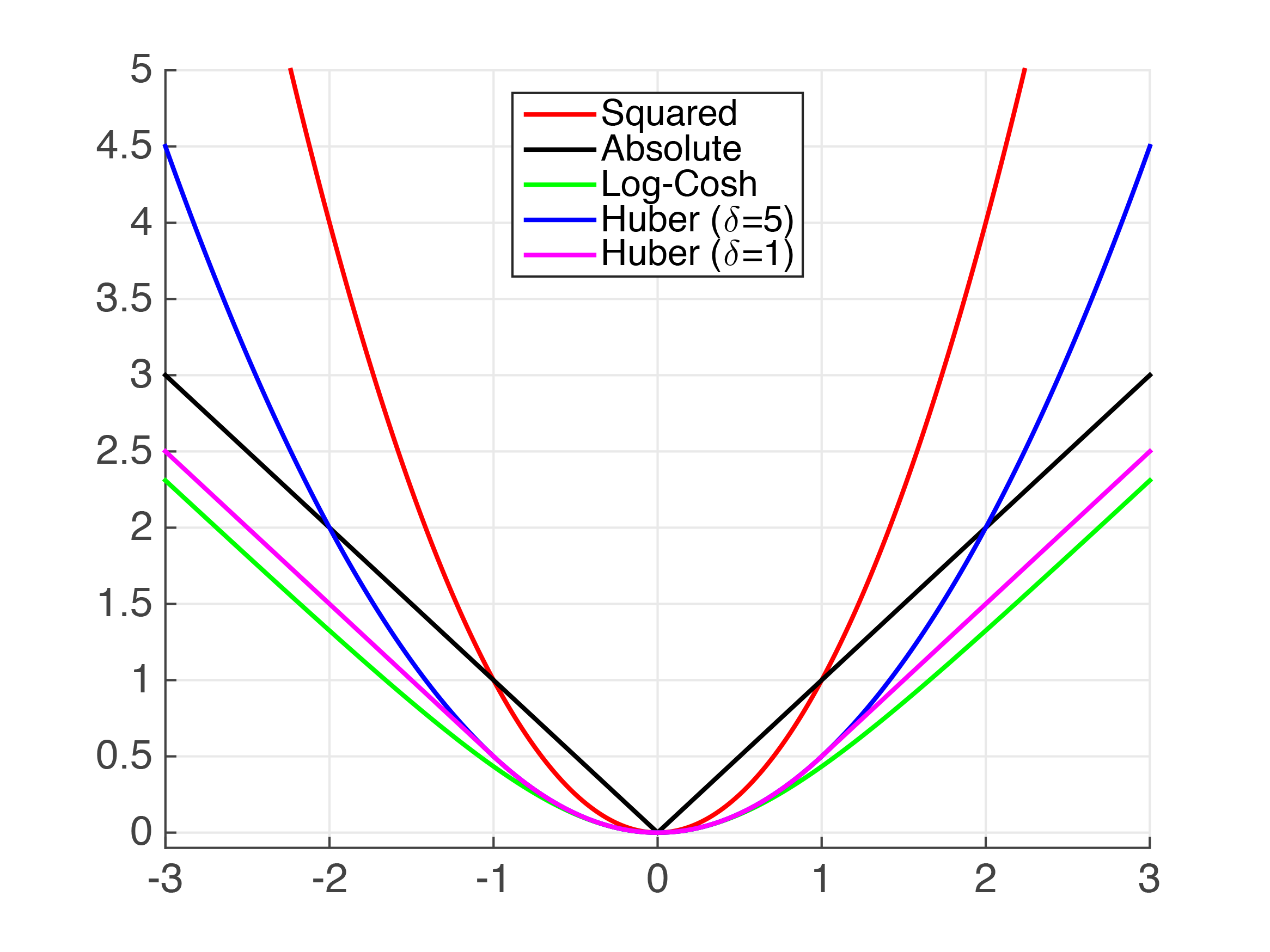
In the squared loss, the biggest loss shadows all the other losses - it wants to use whatever’s possible to decrease the biggest loss. We say the absolute loss is somewhat an “improvement” of the squared loss because it treats all losses more fairly. For example, in squared loss, 10 samples each diff by 1 is 10 loss, but 1 sample differs by 10 is 100 loss. On the other hand, 10 diff by 1 and 1 diff by 10 are both 10 loss in absolute value loss.
Figure 4.2: Plots of Common Regression Loss Functions:
- x-axis: , or “error” of prediction
- y-axis: loss value
Regularizers¶
Remember with Lagrange multipliers, which says for all , there exists such that the two problems below are equivalent, and vice versa.
We can therefore change the formulation of the optimization problem with regularizers to obtain a better geometric intuition:
| Regularizer | Properties |
|---|---|
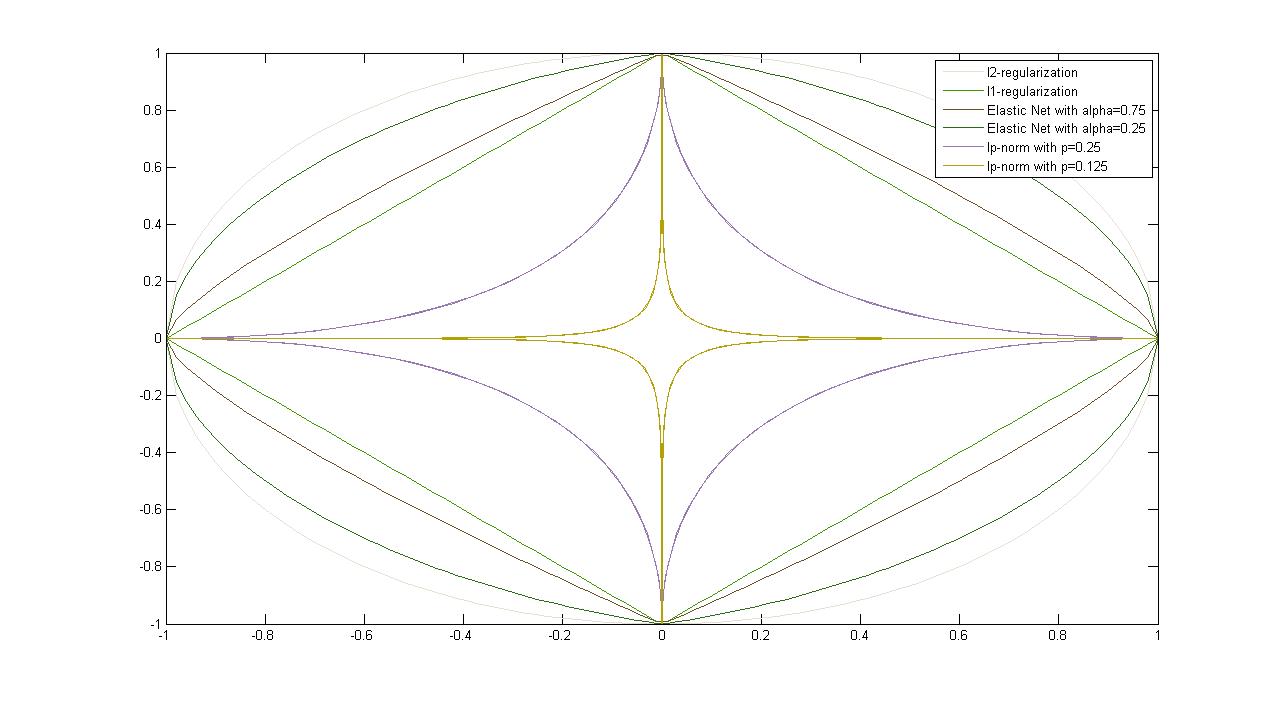
| -Regularization | ADVANTAGE: Strictly Convex, Differentiable DISADVANTAGE: Dense Solutions (it uses weights on all features, i.e. relies on all features to some degree. Ideally we would like to avoid this) |
| -Regularization | Convex (but not strictly) DISADVANTAGE: Not differentiable at 0 (the point which minimization is intended to bring us to) Effect: Sparse (i.e. not Dense) Solutions |
| -Norm | (often ) DISADVANTAGE: Non-convex, Not differentiable, Initialization dependent ADVANTAGE: Very sparse solutions |
Figure 4.3: Plots of Common Regularizers
Famous Special Cases¶
This section includes several special cases that deal with risk minimization, such as Ordinary Least Squares, Ridge Regression, Lasso, and Logistic Regression. Table 4.4 provides information on their loss functions, regularizers, as well as solutions.
| Loss and Regularizer | Comments |
|---|---|
| Ordinary Least Squares | Squared Loss No Regularization Closed form solution: |
| Ridge Regression | Squared Loss -Regularization |
| Lasso | + sparsity inducing (good for feature selection) + Convex - Not strictly convex (no unique solution) - Not differentiable (at 0) Solve with (sub)-gradient descent or SVEN |
| Elastic Net | ADVANTAGE: Strictly convex (i.e. unique solution) + sparsity inducing (good for feature selection) + Dual of squared-loss SVM, see SVEN DISADVANTAGE: - Non-differentiable |
| Logistic Regression | Often or Regularized Solve with gradient descent. $\left.\Pr{(y |
| Linear Support Vector Machine | Typically regularized (sometimes ). Quadratic program. When kernelized leads to sparse solutions. Kernelized version can be solved very efficiently with specialized algorithms (e.g. SMO) |
Table 4.4: Special Cases