SVM - Support Vector Machine
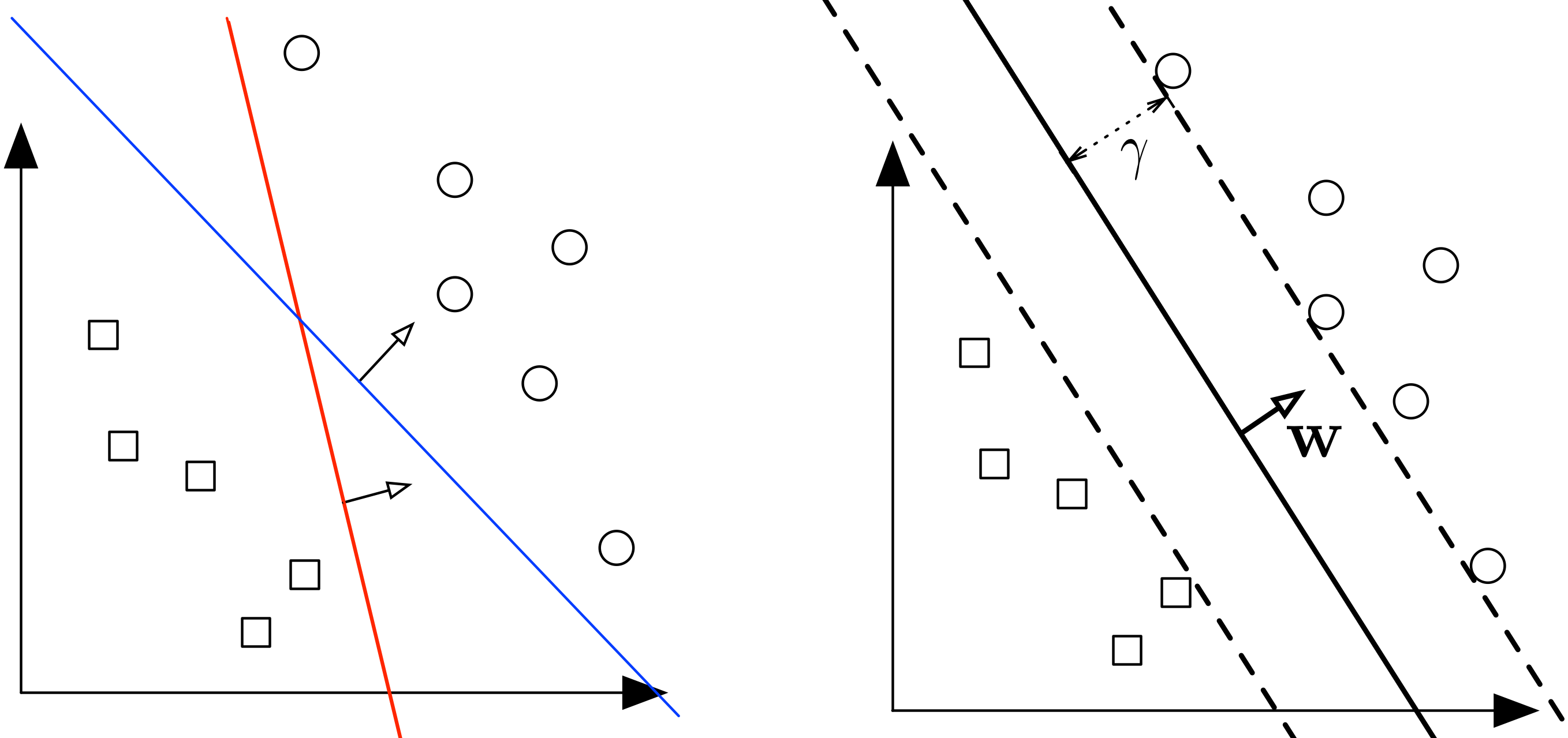
The left picture is what we have achieved so far with a perceptron. The perceptron can give us either the blue line or a red line, so the result does not generalize well. We can view SVM (on the right) as an improvement of the Perceptron - it finds the one that maximizes the distance to the closest data points from both classes. We say it is the maximum margin separating hyperplane.
Defining Margin¶
We know the distance from a point to a plane is .
Using the definition of margin from Perceptron, we have margin of with respect to out dataset is
By definition, the margin and hyperplane are scale invariant:
Max Margin Classifier¶
We can formulate our search for the maximum margin separating hyperplane as a constrained optimization problem. The objective is to maximize the margin under the constraints that all data points must lie on the correct side of the hyperplane:
If we plug in the definition of we obtain:
Maximizing minimum seems almost impossible to do, so we want to remove the in the value we are trying to maximize. We can move this to be a new constraint: Because the hyperplane is scale invariant, we can fix the scale of anyway we want. We choose them such that
so our objective becomes:
Add our re-scaling as an equality constraint to the overall problem, our new optimization problem to solve is:
These two new constraints are equivalent to (Don’t ask me how to do a right to left proof, I do not know), so we can rewrite our optimization problem as:
This new formulation is simply a quadratic optimization problem. The objective is quadratic and the constraints are all linear. We can be solve it efficiently with any QCQP (Quadratically Constrained Quadratic Program) solver. It has a unique solution whenever a separating hyper plane exists. It also has a nice interpretation: Find the simplest hyperplane (where simpler means smaller ) such that all inputs lie at least 1 unit away from the hyperplane on the correct side.
An intuition behind this formula is: the new constraint can be written as . Note this is , so . Since we are minimizing , the only way we can achieve the greater than 1 constraint is to make big. This is exactly what we want.
We can write the prediction result as , so represents classification result correctness. If it is positive, the prediction is correct. And the bigger this value, the more correct we get. If it is negative, the prediction is wrong.
Support Vectors¶
For the optimal pair, some training points will have tight constraints, i.e.
We refer to these training points as support vectors. These vectors define the maximum margin of the hyperplane to the data set and they therefore determine the shape of the hyperplane. If you were to move one of them and retrain the SVM, the resulting hyperplane would change. The opposite is the case for non-support vectors.
SVM with soft constraints¶
If the data is low dimensional it is often the case that there is no separating hyperplane between the two classes, so there is no solution to the optimization problems above. We can fix this by allowing the constraints to be violated (distance of to the hyperplane to be greater than the margin) ever so slight with the introduction of slack variables . At the same time, we don’t want to loose the constraints too much, so we also minimize these slack variables along the way.
As the slack gets larger, we allow point to be closer to the hyperplane , or even on the other side
If C is very large, the SVM becomes very strict and tries to get all points to be on the right side of the hyperplane. If C is very small, the SVM becomes very loose and may “sacrifice” some points to obtain a simpler (i.e. lower ) solution.
Unconstrained Formulation¶
We will express our “SVM with soft constraints” in an unconstrained form.
Note if , so current point is too close (or on the other side) to the plane, is the distance away from the margin point. If point is just as far as other good points, is simply 0. Formulate this in the equation below:
which is equivalent to the following closed form:
This closed form is called the hinge loss. If we plug this closed form into the objective of our SVM optimization problem, we obtain the following unconstrained version as loss function and regularizer:
We optimize SVM paramters by minimizing this loss function just like we did in logistic regression (e.g. through gradient descent). The only difference is that we have the hinge loss here instead of the logistic loss.